
Remote sensing for road detection Part 1: First steps
SkyTruth’s team of interns built a machine learning model to detect one of the holy grails of conservation: roads.
(This is the first in a two-part blog series.)
In July 2020, Technical Program Director Ry Covington and Geospatial Analyst and Programmer Brendan Jarrell invited me, a newly minted SkyTruth intern, to collaborate on a project to detect oil and gas drilling sites (well pads) in satellite imagery. Our work turned a static dataset of known well pad locations into a functional machine learning model capable of quickly and accurately detecting drilling sites in regions with little to no data. With machine learning models we “teach” computers to identify certain characteristics on the landscape. We shared our process in detail in the blog series Drilling Detection with Machine Learning (you can view Part 1, Part 2, and Part 3 with these links).
With that success under our belts as motivation, Brendan envisioned a new application of the technology — detecting roads — and tasked me and my fellow interns with making it a reality. Roads and paths are a fundamental component of any project that expands the built environment. Because their creation often precedes harmful activities like mining, drilling, logging, and poaching, detecting new road construction is one of the holy grails of conservation. This blog post will describe how the intern team adapted the work on oil and gas drilling sites to this new endeavor, give an overview of the model, and explain some of the challenges and solutions encountered along the way. The second post in this series will demonstrate the capabilities of an improved version of the model, and show how this tool can be used to detect change over time.
Changes in Training Data
In Part 1 of our previous blog series, I explained the concept of using Google Earth Engine to create training data through digitizing and sampling Sentinel-2 satellite imagery. To adapt this workflow to roads, we kept the same framework of creating cloud-free, annual composite images from Sentinel-2 and digitizing features visible on those images. The next step also remained similar; namely, generating a binary mask to distinguish the features from the background and taking sample patches from the image and the mask. And, as before, we packaged these samples up in pairs and stored them in a TFRecord, an open source data storage format common in machine learning applications. The fundamental difference was that instead of drawing polygon features to outline well pads, we drew line features to trace roads and paths, and then buffered these lines to capture the width of the roads. This process was much more efficient than manually digitizing the edges of roads, but we needed to account for the differences in width between a narrow street and a major roadway. This resulted in classifying roads as either narrow or wide during the digitizing process, and buffering the line segments by five meters or eight meters respectively as seen in Figure 1.

Figure 1. Left: Narrow, unpaved roads digitized on Sentinel-2 imagery with blue lines and a wide, paved road digitized with a red line around oil drilling sites in New Mexico. Right: The binary mask of the same region, with the narrow roads buffered by five meters on each side and the wide road buffered by eight meters on each side. The red points indicate random locations where we collect samples from the image (left) and the mask (right), to train the road-detection model.
Our team of interns digitized enough roads to create over 5,200 samples, each one a square image “chip” 256 x 256 pixels in size, and four channels deep: three for the Red, Green, and Blue bands of the image and one for the binary indicator on the mask of whether each pixel is a road or not. We used 80% of these samples as training data, and held the remainder separately for validation to show the trained model new examples it had not yet seen.
Reviewing the Segmentation Model
The model chosen for this work is a neural network architecture called U-NET, and Brendan did an excellent job describing its function and communicating machine learning jargon in familiar terms in Part 2 of the earlier blog installment. He also mentioned the purpose of a loss function, which measures the level of error in the model’s predictions. The model, in turn, continuously corrects itself throughout its training process with the intention of minimizing this loss. For the task of segmenting features within a landscape, we have chosen two different metrics, binary cross entropy and Dice coefficient, to combine together to create a comprehensive loss function. Binary cross entropy loss is based on the probabilities that the model assigns to each pixel in an image on how likely it is to be a road. By transforming these probabilities with the log function that increases exponentially, predictions that have a high probability of belonging to their correct class will have a very low loss, while predictions that have low probabilities of belonging to their correct class will have exponentially high loss values. This is suitable for penalizing weak predictions harshly and rewarding strong predictions, which helps the model establish the definite road and non-road pixels before it fine tunes to the less obvious cases. The Dice coefficient is also based on the predicted values of each pixel’s probability of being a road, but in this metric the predicted probabilities are multiplied by their correct class values to compare the area of the model’s correct road predictions with the area of its incorrect predictions (see Figure 2).

Figure 2. The first step in calculating dice coefficient is finding the overlapping intersection (A ∩ B) between the area of predicted roads (A) and the area of actual roads (B). This can be done through matrix multiplication as seen in the top equation (credit to Jeremy Jordan), or it can be done through calculating the areas of layers in a software like QGIS. We multiply this numerator by 2, and divide by the sum of A and B, which includes the incorrectly predicted roads in A (False Positives) and the undetected roads in B (False Negatives). The Dice loss is then derived by the expression 1 – Dice coefficient, since a high Dice coefficient indicates lots of correct predictions and therefore should be correlated to a low loss. Don’t worry if this is hard to grasp at the moment, we will revisit this concept in the next blog with examples!
For further reading about these specific loss functions, check out these blogs on binary cross entropy and Dice loss in segmentation models.
Model Performance and Improvement
With our data prepped and our loss functions defined, we are ready to fit the model to the training data. The model undergoes training for a specified number of epochs (we started with 50).
Every epoch, the model predicts roads for batches of training data samples, calculates the loss of its predictions, and then updates its idea of what a road is accordingly to try to lower its loss on the next epoch. The validation data are assessed after each training iteration, testing the model’s ability to discriminate roads in imagery it has not yet seen. After this training is complete, the true indicator of the model’s performance is not its final minimum loss value, but rather its ability to infer predictions on a brand new image entirely. Figures 3a, 3b, and 3c show how the first rendition of the model predicted roads in different regions.

Figure 3a. The model has confident (bold yellow signifies a higher probability) and accurate predictions on this landscape in Colorado.

Figure 3b. In this forested landscape in Kentucky, the model picks up some roads but isn’t consistent.
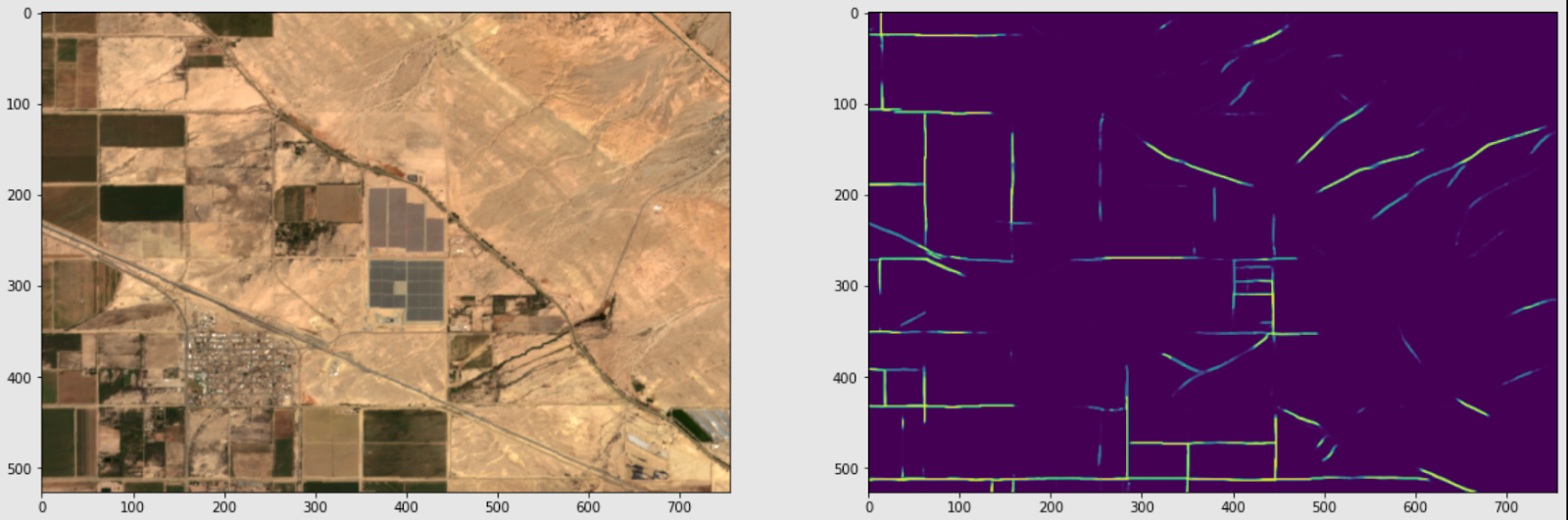
Figure 3c. In this desert region in California, the model predicts some roads correctly but misses some seemingly obvious ones.
Based on these results, it was clear to us that the model was performing well in some cases but lacking in others. When we revisited the training data, we found two potential sources of error. The first one concerned the method used to create sample points. In the well pad project, it made sense to generate one sample point near each polygon. But when we applied this technique to roads, it led to several sample points being generated in close proximity to each other. (See Figure 4 of a training data collection location in Midland, Texas.)

Figure 4. In this region, the roads were very close together and very short, meaning we had to create new lines for almost every road. This led to a dense cluster of sample points (red dots) on the left side of the top image, and this may have caused some bias by over-representing that landscape in the training data. As a solution, I was able to distribute the sample points randomly across the image bounds as seen in the bottom image. This spreads out the samples and avoids emphasizing one area over another.
The second potential source of error was a similar problem but on a macro scale. Because most of our training data came from states like Colorado, Utah, New Mexico, and Texas, the data all shared similar characteristics. For example, the majority of roads appeared in the images as a shade of white against a brown background. This explains why the model performed poorly in dark green forest and light sandy desert regions, so we knew we had to add more variation into our training data if we wanted the model to be generalizable to other landscapes. As a result, we added around 1000 samples from areas with dense vegetation and areas where the roads appeared darker than their background.
While we were retracing our steps to improve the model, another idea came to mind. If adding more diverse landscapes could increase the complexity of the model by expanding the visual definition of what a road looks like, what if we could leverage information beyond the optical Red-Green-Blue bands? That is, would including the Near Infrared, Shortwave Infrared, or other spectral bands of Sentinel-2 images lead to significant improvements in the model’s ability to detect roads?
I’ll explore those questions in my next blog post.
SkyTruth interns Hillson Ghimire, Dylan Thomson, Dhiya Sathananthan, Cameron Reaves, and CJ Manna contributed to this project and this blog post.
(Note: Title was adjusted 7/20/21)

