Matthew Ibarra’s Final Project Was His Favorite
As a SkyTruth Intern, Matthew Ibarra learned new skills and helped protect Native lands.
As I finish up my internship at SkyTruth, I can honestly say that the experience has been everything I imagined it would be and more. My time here was a perfect amalgamation of what I love: namely, an organization that applies technology and gathers and analyzes data to protect the environment.
When I started my internship at SkyTruth I was unsure of what to expect. I remember the first day I drove into the small town of Shepherdstown, West Virginia. I was worried. For the first time in my life I was working with like-minded individuals with special talents and skills far above my own. I thought that I would have to perform as well as my colleagues right off the bat. However, my fears quickly melted away upon meeting Brendan Jarrell, SkyTruth’s Geospatial Analyst and father to all us interns. Brendan assured me that I would be focusing on my own personal interests, developing practical skills, and applying them to the various projects happening at SkyTruth. Within my first week I became familiar with all the programs I needed for my internship, namely Google Earth Engine and QGIS. Both are programs that are critical in geospatial analysis that were completely new to me, despite having taken Geographic Information System (GIS) courses at West Virginia University. Interning at SkyTruth opened my eyes to the new possibilities of environmental monitoring and I was excited to get started.
My very first day I became familiar with the various satellites that orbit the Earth and provide the imagery that SkyTruth uses on a daily basis. The Landsat and Sentinel satellite missions provide imagery available for free to the public, allowing interns like myself to create maps and interactive data to track activity on Earth. My first task as an intern was to monitor Southeast Asian waters for bilge dumps — oily slicks of wastewater dumped in the ocean by ships. I used Google Earth Engine to access the necessary imagery easily. Then I used QGIS to create the various maps that we post on our Facebook page and blog posts. I found my first bilge dump on February 7, 2020. It was a 35 kilometer slick (almost 22 miles long) off the coast of Malaysia.
Often, we can identify the likely polluter using Automatic Identification System (AIS) to track vessels at sea. Most vessels constantly send out a radio signal to broadcast their route. When those signal points align with a bilge dump it suggests that the ship is the likely source for that bilge slick. However, not all ships will transmit their signal at all times, and there have even been instances of ships spoofing their signal to different locations. For my first slick I was unable to match a ship’s AIS broadcast to the trail of the bilge dump, but I was able to do so several times after that. We can’t know for certain who caused this slick, but imagery helps us paint a picture of potential suspects. My first slick pales in comparison to the many slicks I found in later months: later, I captured a few slicks that were over 100 kilometers (more than 62 miles) in length. I was also able to link a ship’s AIS broadcast to the trail of the slick. You can read more about slicks in the South East Asia region in my April 15 blog post here.

An example of likely bilge dumping from a vessel identified using Sentinel satellite imagery
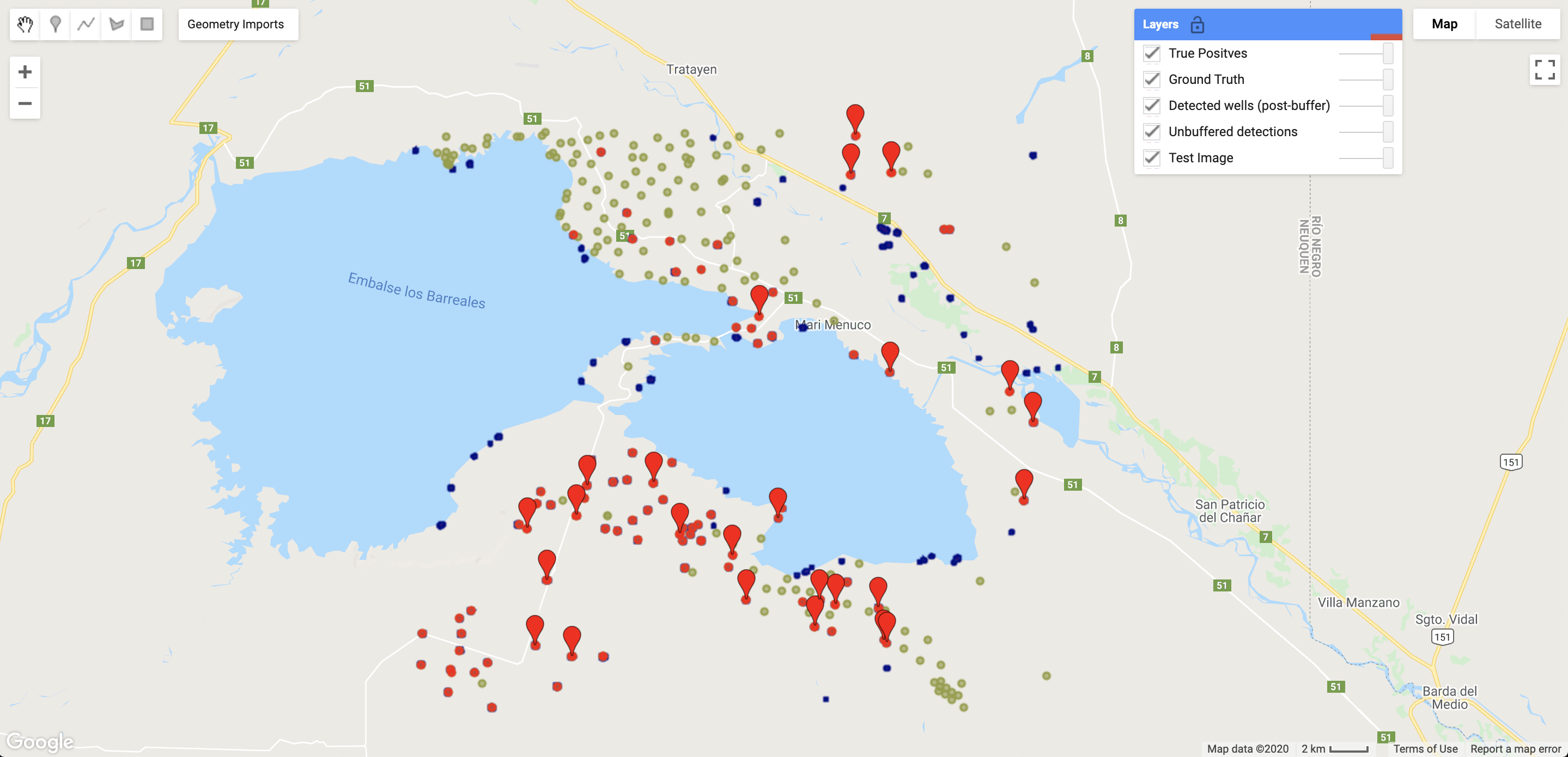
Following my introduction to our bilge dumping detection work, I was thrilled to be assigned my first solo project for SkyTruth — updating SkyTruth’s FrackFinder. FrackFinder is an ongoing project at SkyTruth. It aims to keep track of the active oil and natural gas well pads in states such as West Virginia. Drilling permit data is often misleading; sites that are permitted to be drilled may not actually be drilled for several years. In the past, our FrackFinder app was hosted in Carto. Carto is a cloud-based mapping platform that provides limited GIS tools for analysis. I was tasked with giving the application an overhaul and bringing it into Google Earth Engine, a much more powerful and accessible program.
Learning to code for Earth Engine was challenging for me. I had only one computer science course in college, and that was nearly three years ago. So I was surprised that my first project would revolve around coding. Initially, I was overwhelmed and I struggled to find a place to start. As time went on I slowly became more comfortable with spending large amounts of time solving tiny problems. Brendan was incredibly helpful and patient with teaching me everything I would need to know to be successful. He always made time for me and assisted me with my code numerous times. My finished app is far from perfect but I am proud of the work that I accomplished and I hope that it brings attention to the changing landscape of West Virginia caused by oil and natural gas drilling using hydraulic fracturing (fracking).
The FrackTracker app for West Virginia
My second and final project was creating a visualization about the land surrounding Chaco Culture National Historical Park in New Mexico. Much like the update to the FrackFinder App, it involved the changing landscape surrounding the park due to the increase in fracking. I was tasked with creating a series of still images, an embeddable GIF which shows an animation of the rapid increase in drilling, and an app on Earth Engine that allows the user to zoom in and visually inspect each individual well surrounding the park. In the final months of my internship, I became comfortable using the programs that were foreign to me initially. I created a series of 19 images using QGIS from the years 2000-2018. You can see the collection of images for each year here. SkyTruth’s Geospatial Engineer Christian Thomas assisted me in creating the GIF.
This project was special to me because I was able to help activists who are advocating for the passage of the Chaco Cultural Heritage Area Protection Act, legislation passed by the U.S. House of Representatives that would effectively create a 10-mile buffer zone surrounding the park and ensure the protection of the area for Native Americans and local communities for generations to come. The Senate has not yet passed the act. When I started my internship at SkyTruth I never would have believed that I would be advocating for protection of Native lands. I always believed issues like these were too big for one person to tackle, but if there’s anything I learned at SkyTruth is that only one person can create real change.
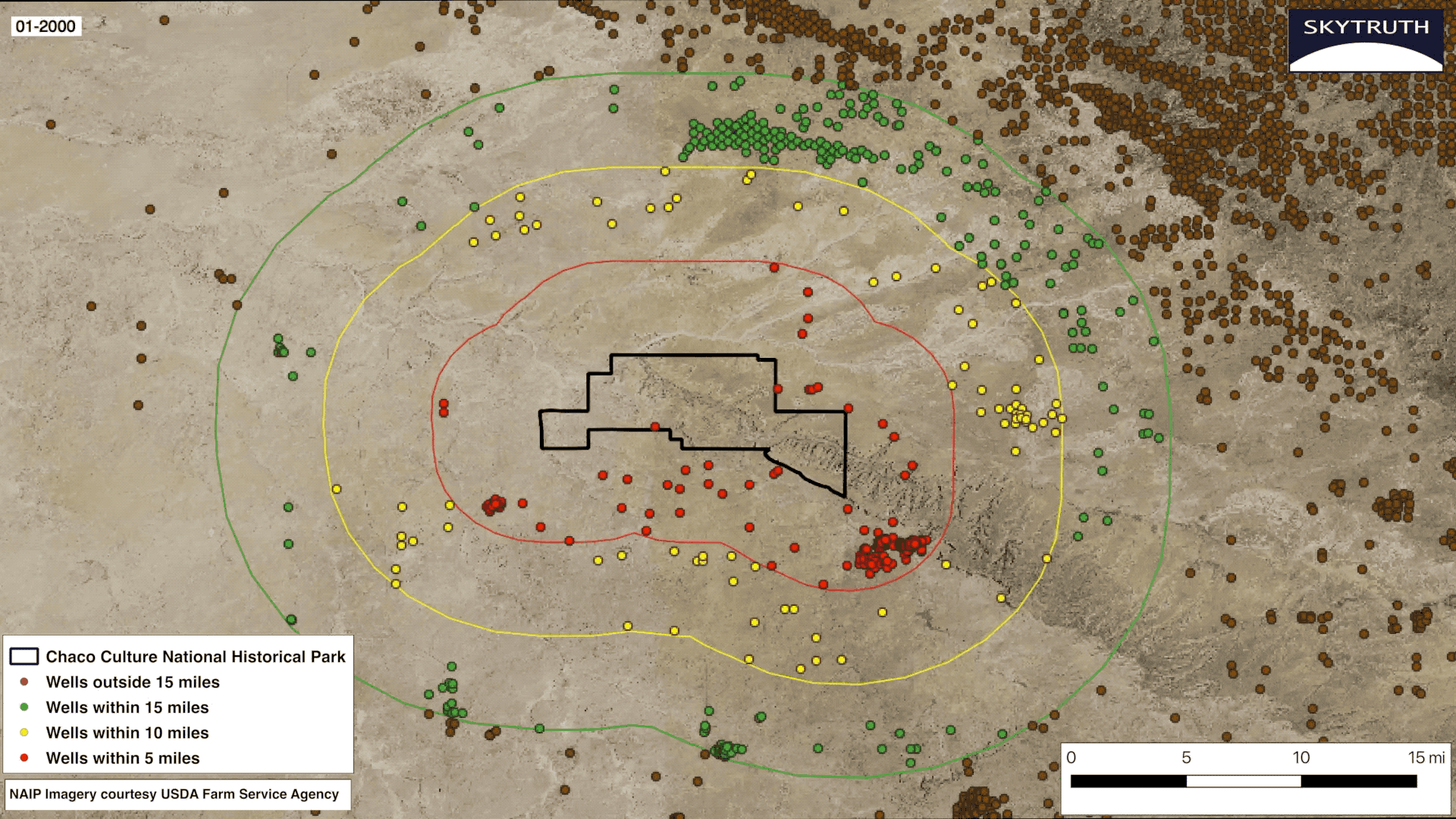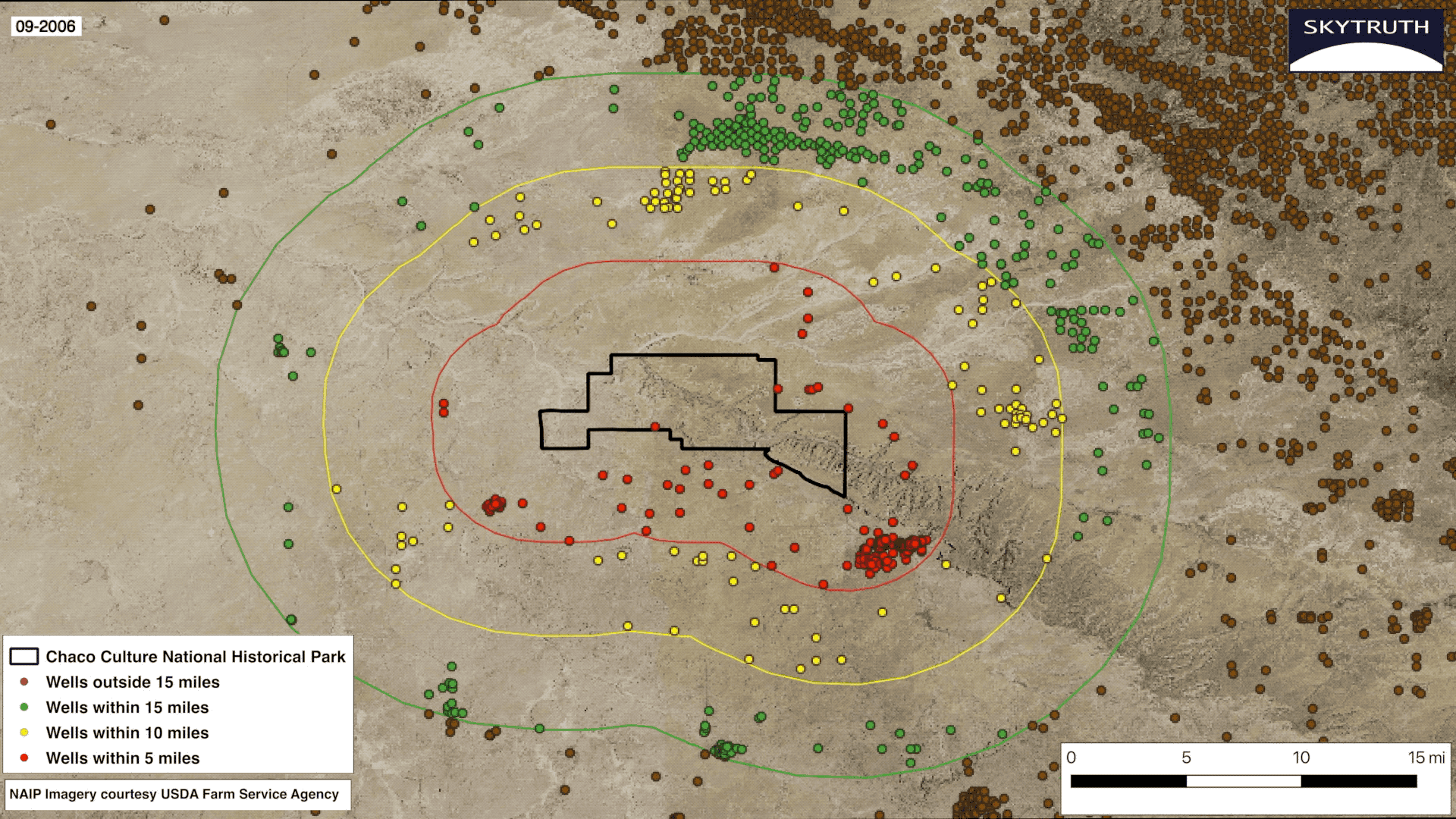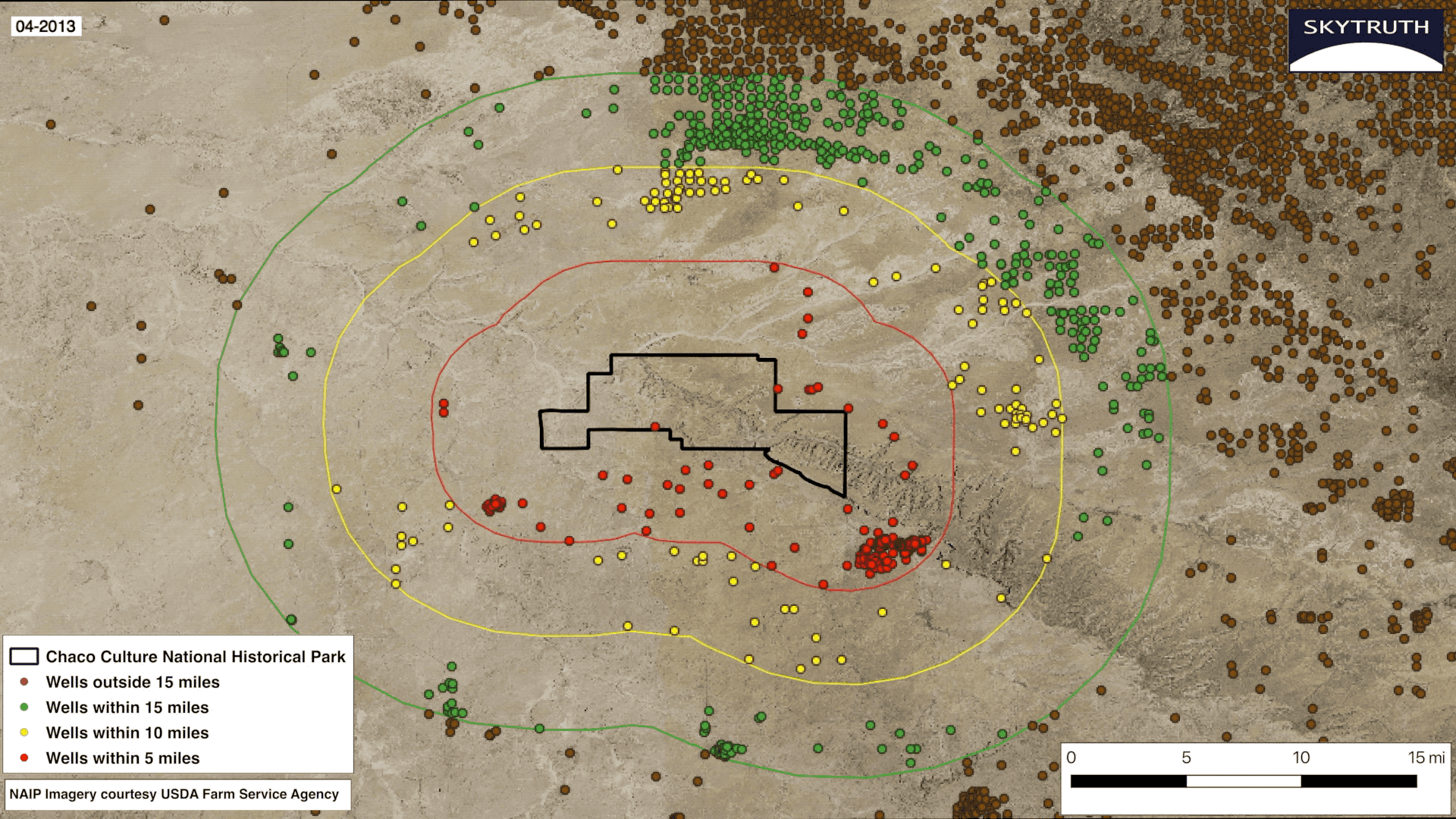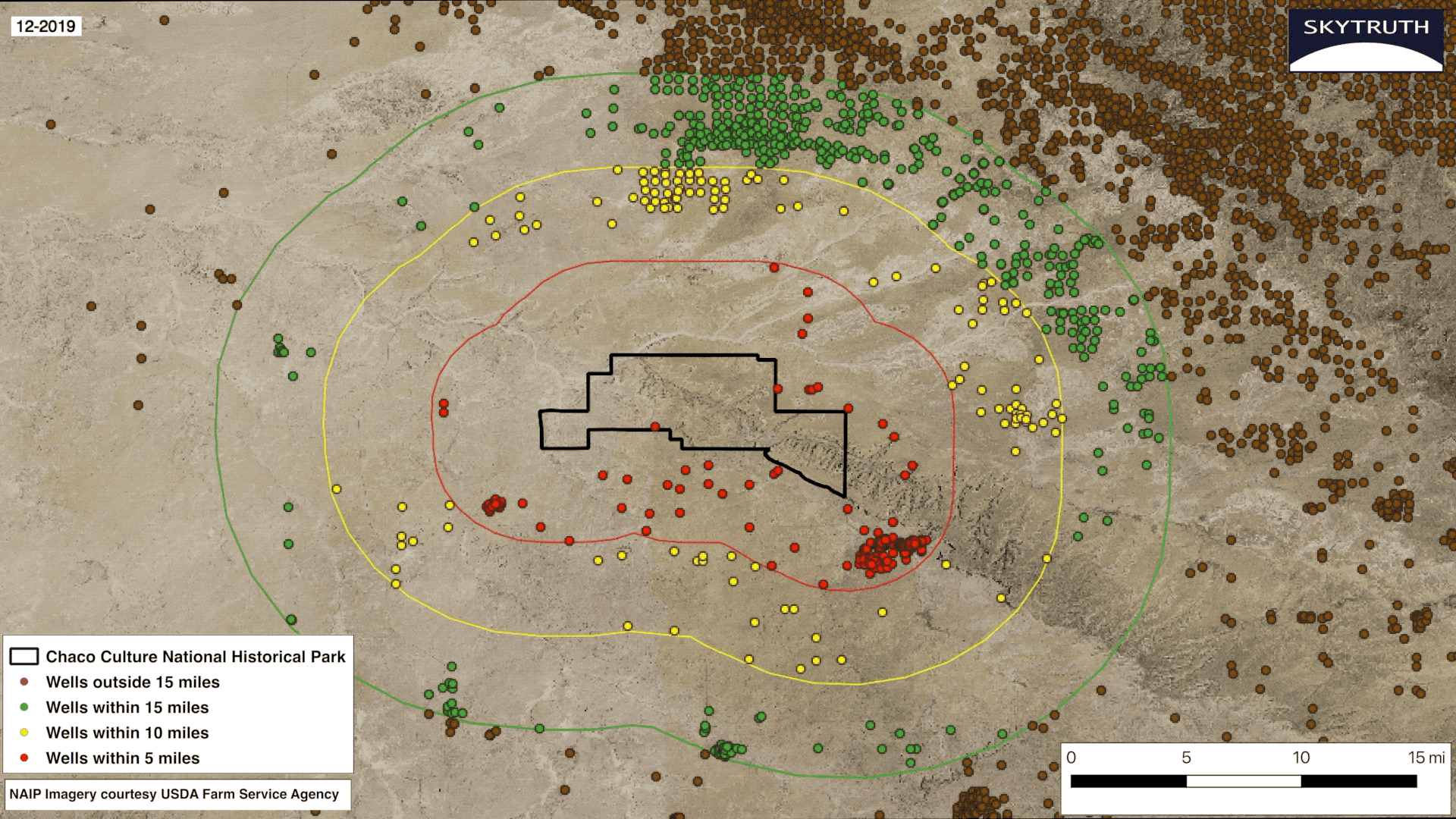
The growth of oil and gas wells within a 15-mile radius of Chaco Culture National Historical Park from 2000 – 2018
After interning at SkyTruth for the past eight months I am happy to say that I feel I have made a difference in the world. I accomplished so much that I thought would be impossible for me initially. I used to think oil slicks were tragedies that happened infrequently, limited to a few times a decade. I was shocked to learn that oily wastewater gets dumped into the ocean so frequently that I was able to capture more than 80 bilge dumps in my eight months at SkyTruth.
In addition, one of my greatest passions is sustainable energy. I was thrilled to be an advocate for clean energy by showcasing the dangers of an ever-expanding oil and natural gas industry. West Virginia has been my home for the past five years during my time at West Virginia University and I was happy to be able to bring to light one of the growing concerns of the state through the 2018 FrackFinder update. Finally, I was able to advocate for the protection of Native lands through the most meaningful project to me — the Chaco Culture National Historical Park visualizations. It felt incredible fighting for something that was much bigger than myself. As I leave SkyTruth, I will miss contributing to the world in my own way.
SkyTruth has always been more than just a place to intern at for me. I have made unforgettable connections with my colleagues despite the various challenges that we all have to face every day, such as the ongoing COVID-19 pandemic. Never once did I feel that I was alone in my work. I always knew there were people supporting me and encouraging me in my projects even when I was working remotely. I will never forget Christian’s tour of Shepherdstown on my first day or Brendan’s talks about the best Star Wars movie. I cannot thank each of them enough for the patience and kindness they showed me in my short time with them. Everyone at SkyTruth has contributed to my success in some way. I will miss everyone, but I’ll carry my new skills and experiences with me for the rest of my life.